Big Data
Vraag 1:
Businessidee:
→ Starten van een bedrijf dat tweedehands elektrische fietsen verkoopt en verhuurt.
Waarom dit idee?
- Elektrische fietsen ("e-bikes") zijn populair geworden door duurzaamheidstrends, vergrijzing, en de wens om files te vermijden.
- Tweedehands maakt het betaalbaarder, zeker in tijden van economische onzekerheid.
- Door zoekdata kunnen we nagaan of de interesse in tweedehands e-bikes groeit, daalt of stabiel blijft.
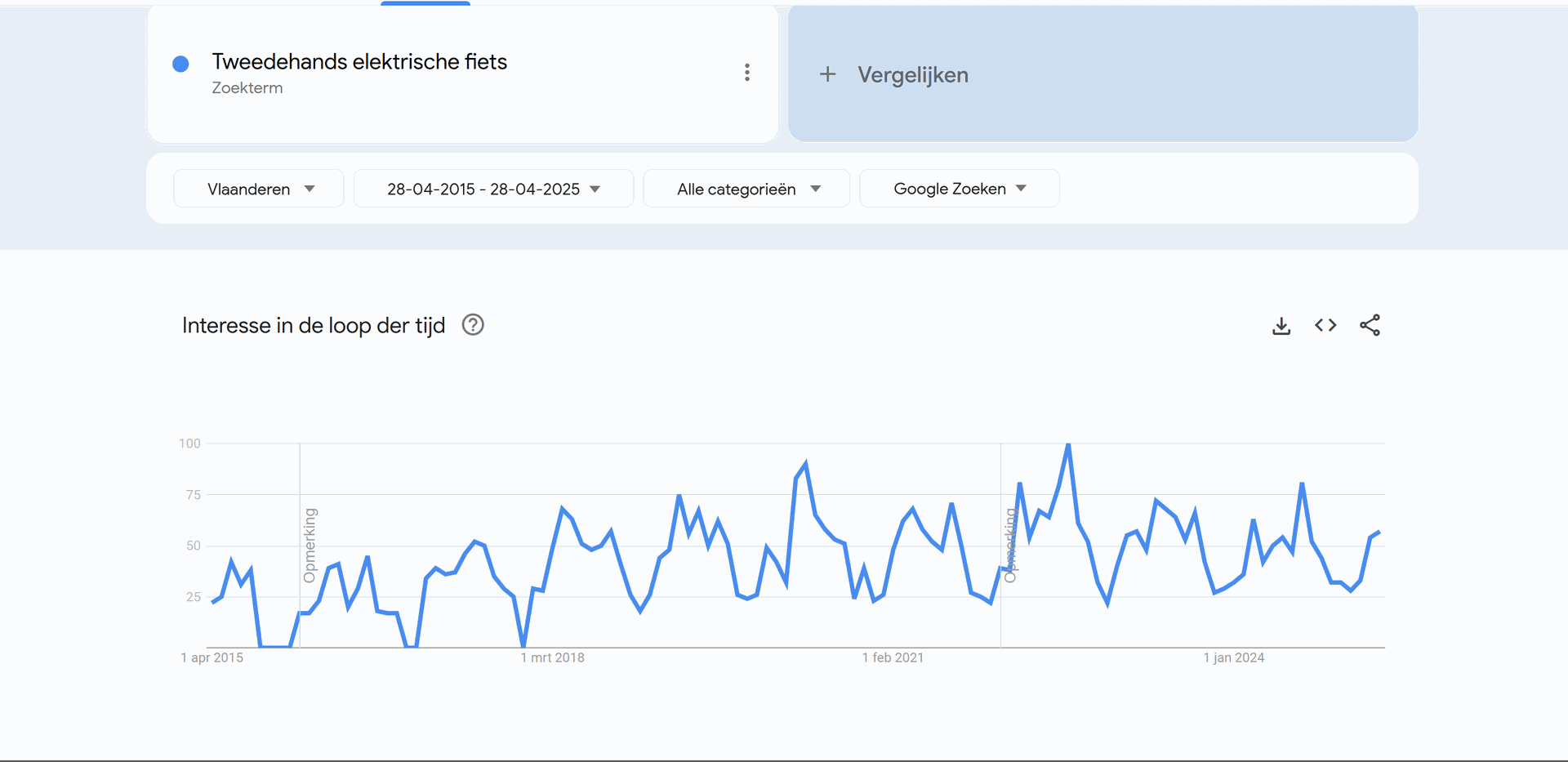
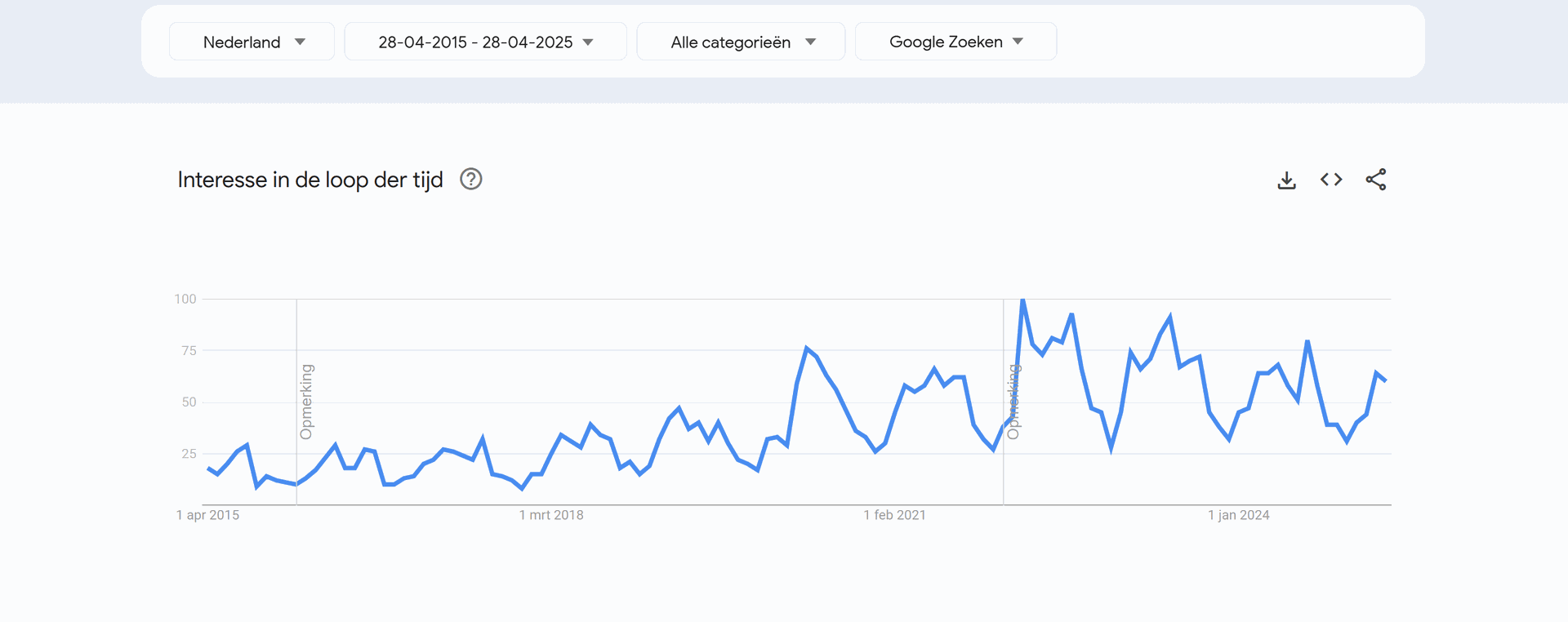
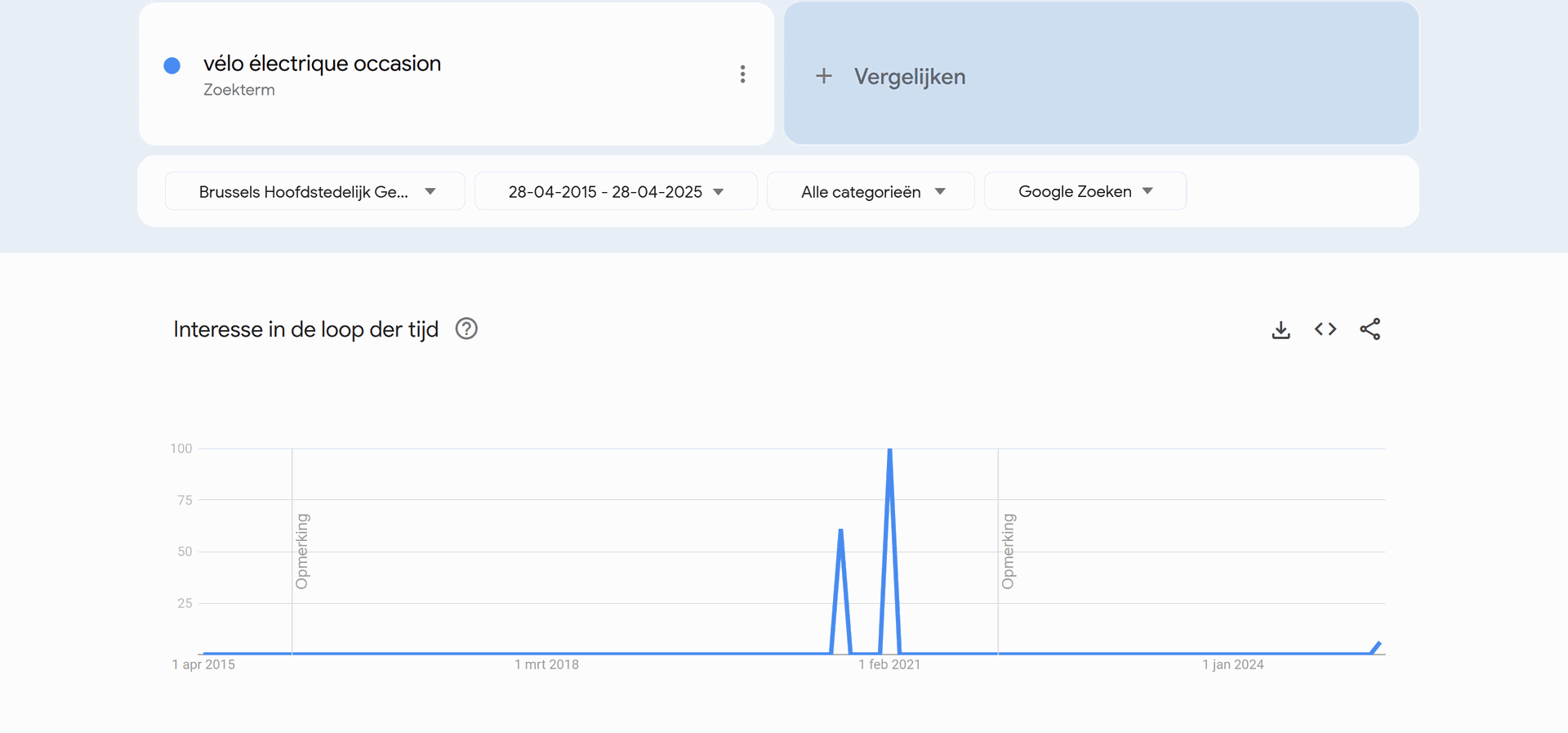
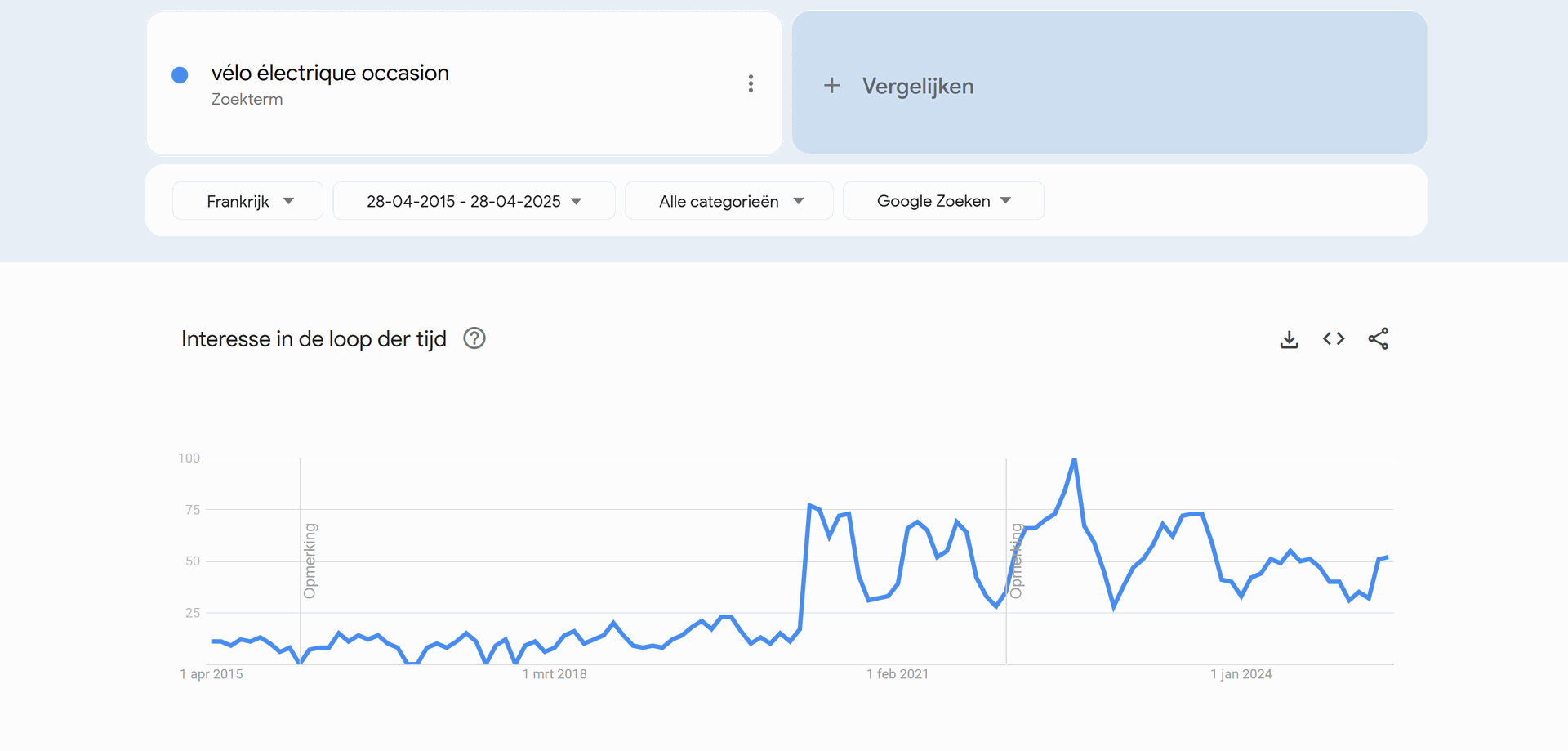
Bij het zien van deze data, zien we dat in Vlaanderen en Nederland significant meer gezocht wordt naar elektrische fietsen, dan dit in Wallonië, Brussel en Frankrijk gedaan wordt. Wanneer mijn bedrijf dus zijn opstart begint, zal het zich hoofdzakelijk richten tot de Vlaamse en Nederlandse markt. Hierbij zien we geen groot verschil tussen beide.
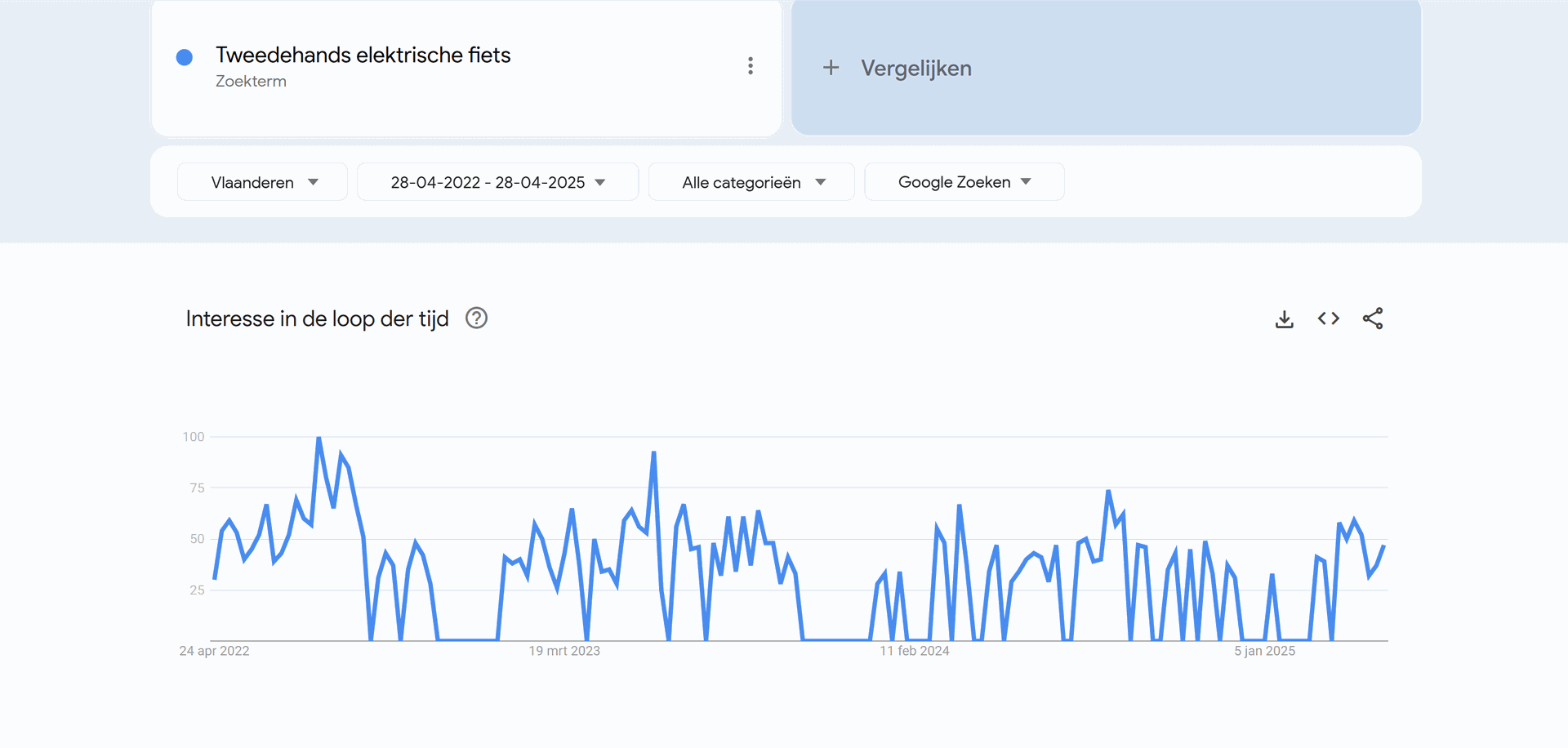
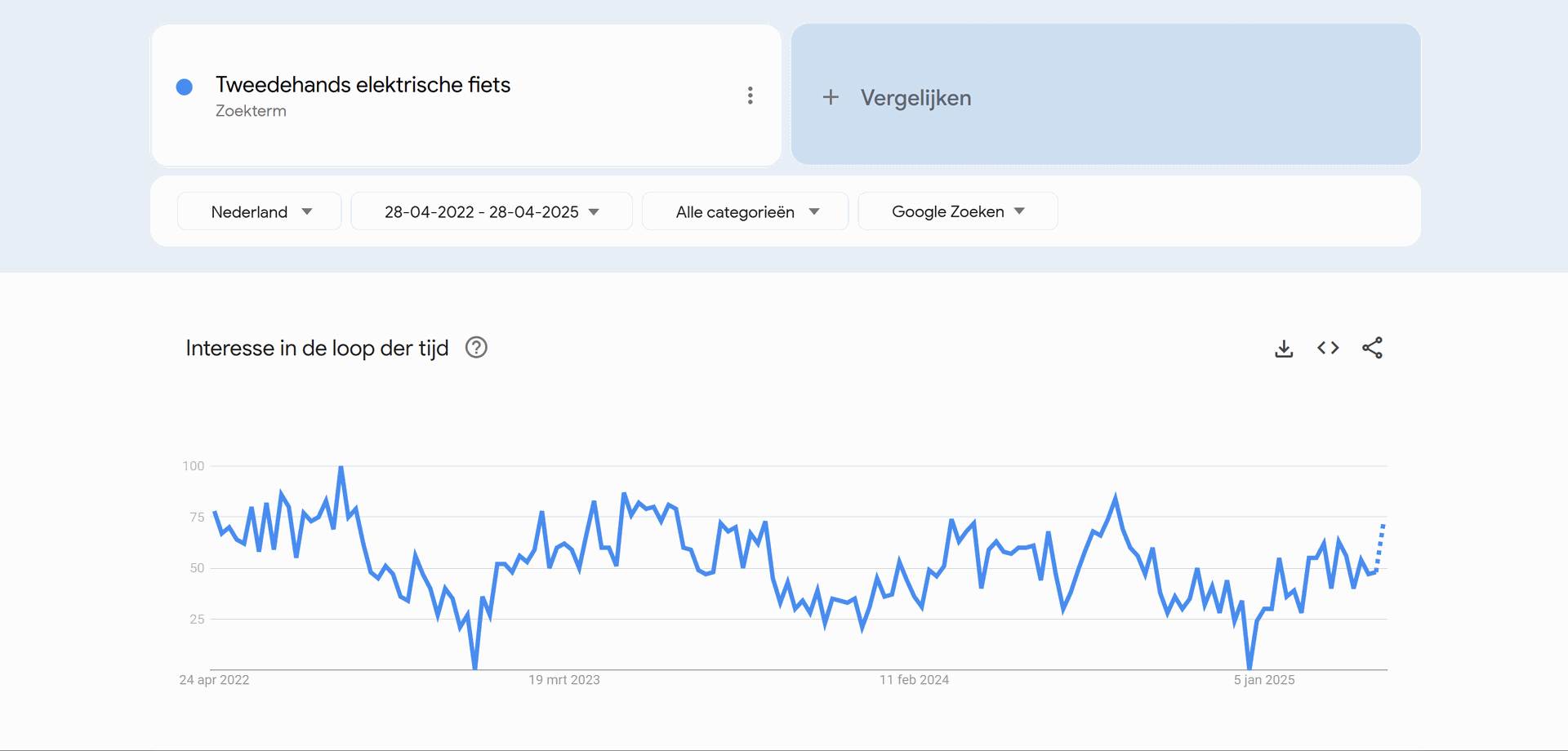

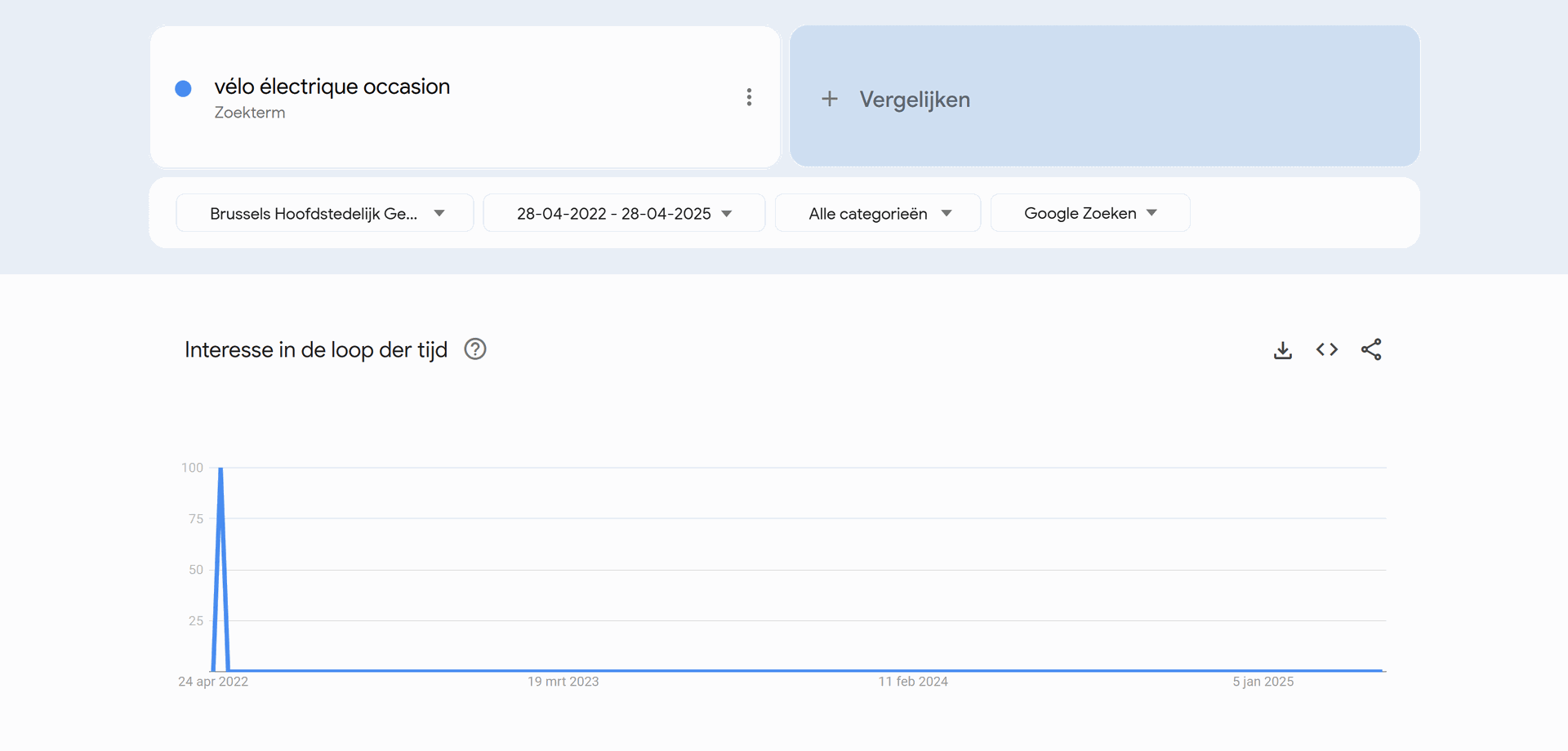
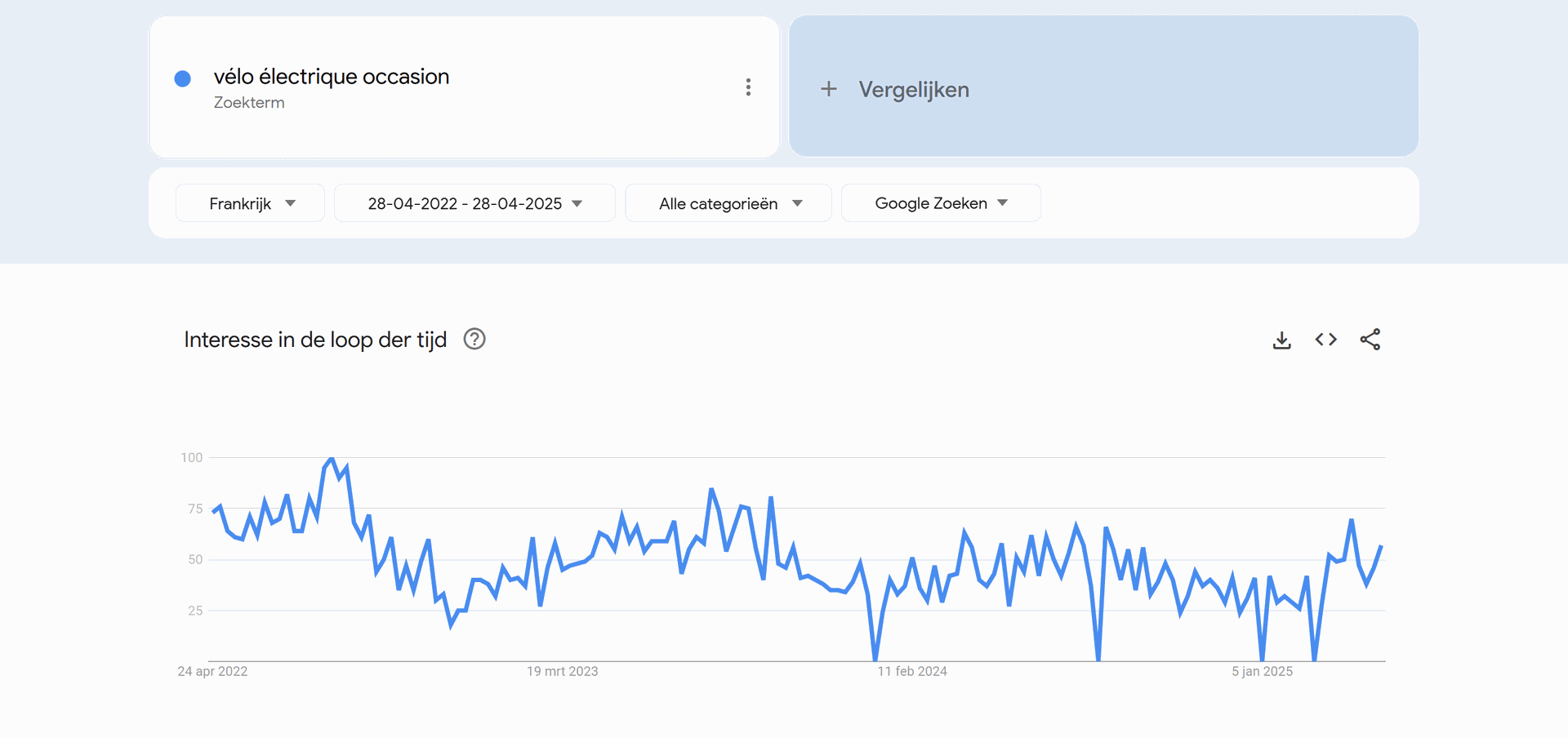
Zowel in Frankrijk, Vlaanderen alsook Nederland is er een piek in het aantal zoekopdrachten naar elektrische tweedehandsfietsen tijdens de zomermaanden. Dit loopt hoofdzakelijk vanaf april tot september. Tijdens deze maanden zal het bedrijf dus moeten zorgen dat ze extra inzetten op de nodige marketing en voldoende voorraad voorzien.
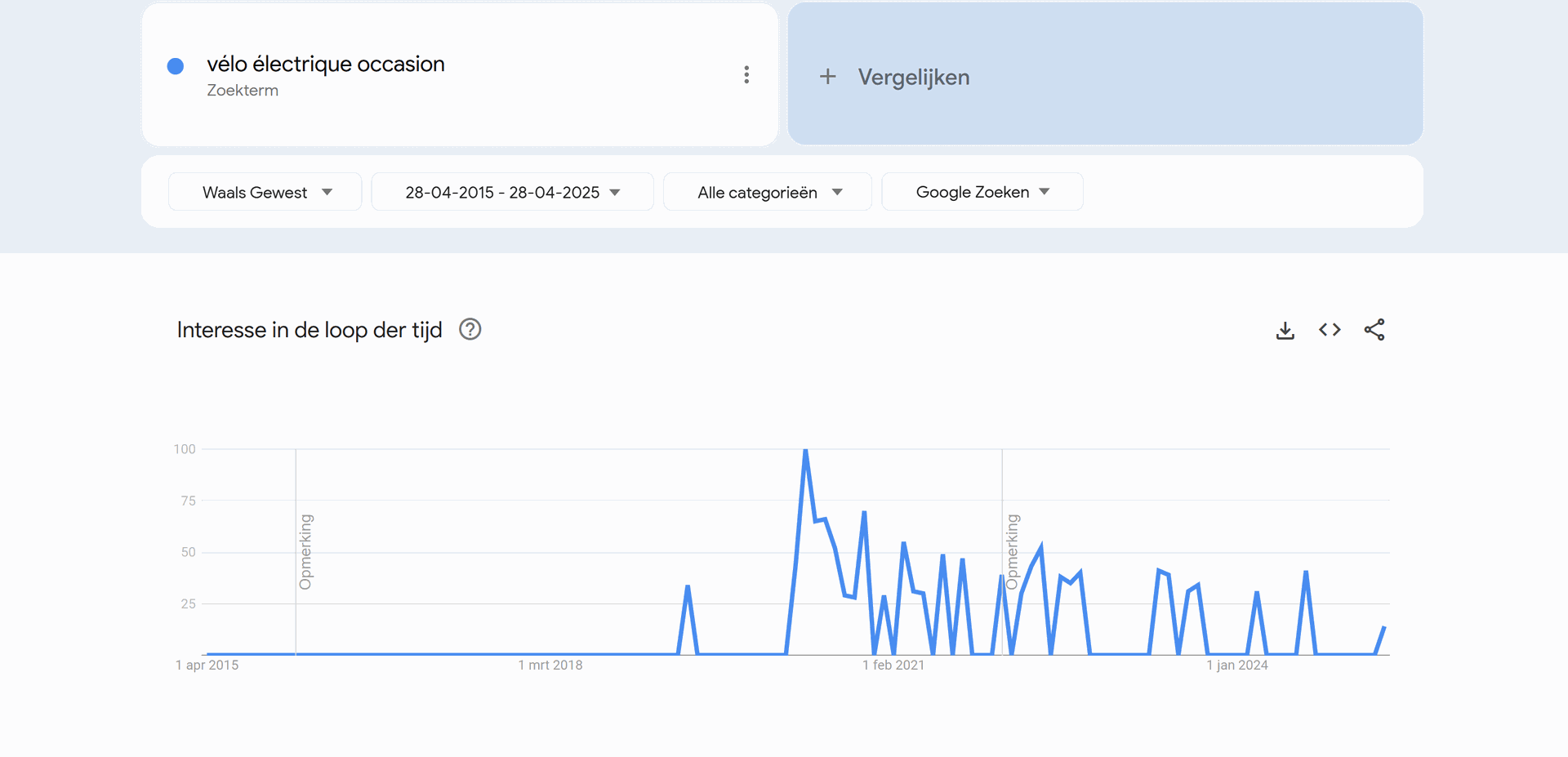
d. Zijn er geografische verschillen? Stel dat je in Frankrijk wil starten met de verkoop, maar eerst in één regio van Frankrijk. Welke regio kies je dan?
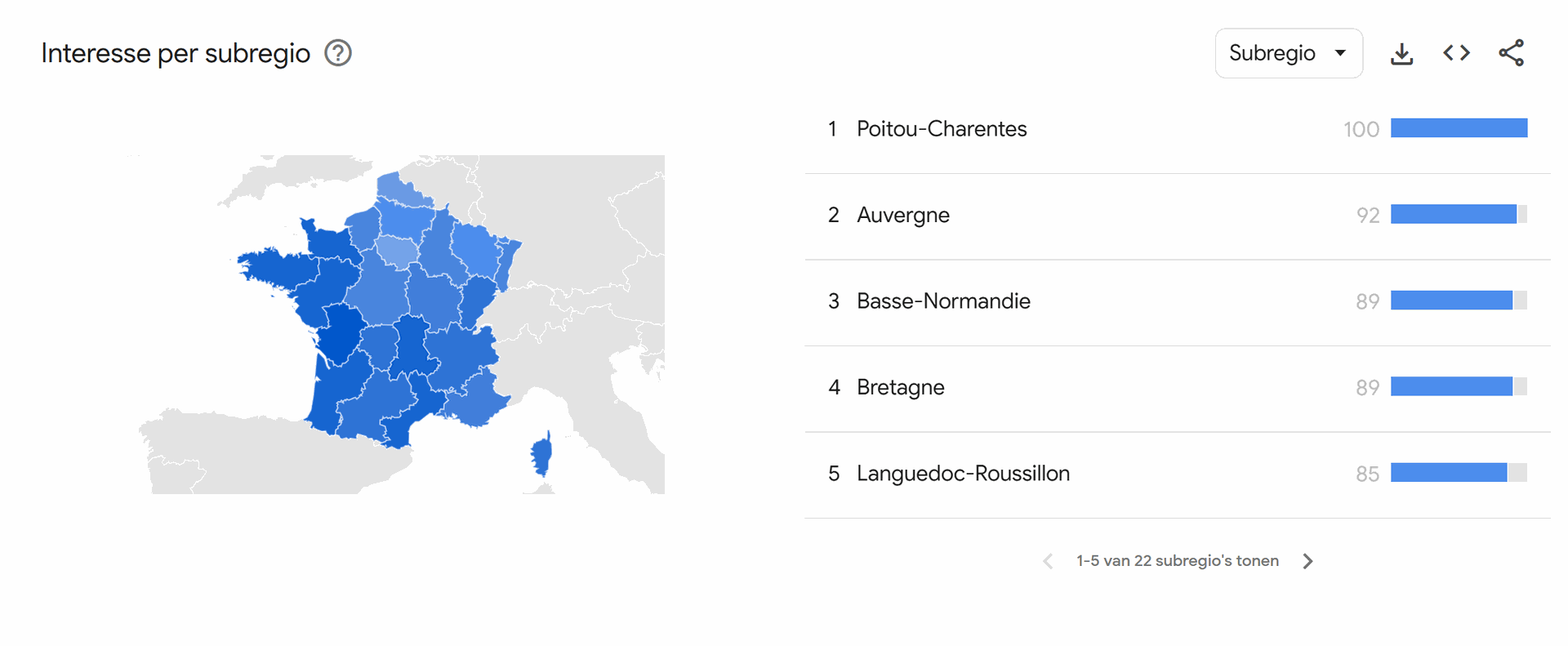
Met de zoekterm: vélo électrique occasion wordt gemerkt dat vooral in het westen van Frankrijk met name de regio: Poitou-Charentes vraag is naar tweedehands elektrische fietsen. Dit is wel nog steeds significant lager dan in Vlaanderen en Nederland. Daarom zou ik zelf misschien eerder kijken om de markt elders uit te breiden dan Frankrijk.
Vraag 2:
Wat zijn typische voorbeelden van “Veracity” onbetrouwbaarheids oorzaken? (selecteer alle juiste antwoorden). Je zal wat desk research moeten doen om eerst te begrijpen wat deze termen betekenen, en dan rekening houden met wat Veracity betekent in de context van Big Data.
- Web brigade
- Data quality
- AI generated content
- Sock puppet
- Bots
- Digital footprint
Vraag 3:
Data Sources Brainstorm
Probeer zoveel mogelijk verscheidene concrete bronnen van big data te identificeren voor het domein "smart city". Geef telkens in één zin een voorbeeld van datageneratie van zo'n bron (Sensoren, voertuigen, mensen, bestuur, socials,...). Wees voldoende concreet.
🚦 Mobiliteit & Verkeer
- Verkeerssensoren: Infrarood-lussen meten voertuigen op kruispunten.
- Openbare vervoersystemen: GPS in bussen geeft live vertragingen door.
- Navigatieapps: Waze-gebruikers leveren data over files.
- E-steps en deelfietsen: GPS-tracking rapporteert ritten en parkeerlocaties.
- Mobiele telefoons: Locatiedata toont voetgangers- en verkeersstromen.
- Logistieke data: Pakketdiensten volgen voertuigen en bezorgingen.
🏙️ Infrastructuur & Stedelijke ruimte
- Slimme straatverlichting: Bewegingssensoren passen licht aan bij detectie van voetgangers.
- Parkeersensoren: Sensoren registreren vrije en bezette parkeerplaatsen.
- Crowdsourcing-apps: Burgers melden schade of defecten in de openbare ruimte.
- Beveiligingscamera’s (CCTV): Livebeelden van drukke pleinen voor toezicht.
🌱 Milieu & Duurzaamheid
- Weersensoren: Weerstations meten temperatuur, vochtigheid en wind.
- Milieu sensoren: Luchtkwaliteitsmeters monitoren fijnstofniveaus.
-
Watermanagementsystemen: Rioleringssensoren meten waterpeil.
- Slimme afvalcontainers: Sensoren detecteren wanneer bakken vol zijn.
🔋 Energiebeheer & Gebouwen
- Slimme energiemeters: Verbruik wordt elk kwartier geregistreerd.
- Slimme gebouwen: HVAC-systemen meten energiegebruik en CO₂-niveaus.
🧑🤝🧑 Maatschappij & Gezondheid
-
Gezondheidssensoren: Slimme horloges meten hartslag en andere parameters
🏛️ Bestuur & Openbare diensten
- Overheidsdatabases: Real-time vergunningen en openbare werken via open data.
- Gebeurtenisdatabases: Data over geplande evenementen die drukte beïnvloeden.
Vraag 4:
Wat kan organisaties helpen om nieuwe verbanden te vinden en patronen te ontdekken die aanzienlijk bijdragen aan veiligheid, toezicht en informatiegaring? (selecteer hieronder het goede antwoord)
- satellietdata
- eigen servers
- GPS data
- XML
- analyse van data “in-motion” en “at rest”
Vraag 5:
Hoeveel petabytes zitten er in een exabyte ? (selecteer hieronder het goede antwoord)
- 256
- 1 048 576
- 1024
- 8
Vraag 6:
JSON en XML zijn twee voorbeelden van semistructured data. Doe wat desk research, en geef dan een eenvoudig voorbeeldcode van een stukje semistructured data in naar keuze JSON of XML. Leg vervolgens in grote lijnen uit hoe je die JSON of XML moet interpreteren of "lezen". Waarom noemt men dit feitelijk "semi-structered" en niet "structured"?
JSON:
{
"stad": "Gent",
"temperatuur": 18,
"weersomstandigheden": {
"beschrijving": "bewolkt",
"wind": {
"snelheid_kmh": 15,
"richting": "ZW"
}
},
"tijdstip": "2025-04-28T14:00:00Z"
}
XML
<weerrapport>
<stad>Gent</stad>
<temperatuur>18</temperatuur>
<weersomstandigheden>
<beschrijving>bewolkt</beschrijving>
<wind>
<snelheid_kmh>15</snelheid_kmh>
<richting>ZW</richting>
</wind>
</weersomstandigheden>
<tijdstip>2025-04-28T14:00:00Z</tijdstip>
</weerrapport>
De data beschrijft een weerbericht voor de stad Gent.
De temperatuur bedraagt 18 graden.
De weersomstandigheden zijn "bewolkt", met een wind die 15 km/u waait vanuit het zuidwesten (ZW).
Het tijdstip van de meting is 28 april 2025 om 14:00 uur (UTC-tijd).
Zowel in JSON als XML worden deze gegevens hiërarchisch voorgesteld: eerst algemene informatie (stad, temperatuur), vervolgens details over het weer (beschrijving en wind), en uiteindelijk het tijdstip.
JSON en XML hebben wel een bepaalde structuur, maar ze zijn niet zo strikt als bijvoorbeeld een relationele database. Er zijn regels over hoe data georganiseerd wordt, maar je kunt flexibel velden weglaten, nieuwe toevoegen of verschillende types gebruiken zonder dat alles meteen fout gaat. Omdat er dus wel structuur is, maar niet alles vastligt, noemen we dit semi-structured data.
Vraag 7:
Op welk type data ligt de focus bij Operations Analysis? (selecteer hieronder het goede antwoord)
- Location Data
- Machine Data
- Binary Data
- Social Media Data
- Structured Data
Vraag 8:
Gebruik van big data voor het behoud van kostbare bossen
Big data speelt een steeds belangrijkere rol bij het beschermen van waardevolle natuurgebieden. Een concreet voorbeeld hiervan is de inzet van de zogenoemde High Carbon Stock (HCS) Approach door Greenpeace. Met deze methode worden ’s werelds meest kostbare bossen, die rijk zijn aan koolstofvoorraden, nauwkeurig in kaart gebracht. Big data worden hierbij gebruikt om factoren als biodiversiteit, vegetatiedichtheid en koolstofopslag te analyseren.
Veel bedrijven willen hun bevoorradingsketens verduurzamen, maar weten niet goed hoe zij dat moeten aanpakken. Door gebruik te maken van de HCS-methode kunnen zij duidelijk onderscheid maken tussen bossen die beschermd moeten blijven, en gebieden die al in een verslechterde staat verkeren en daardoor beter geschikt zijn voor het winnen van grondstoffen zoals palmolie en rubber. Op deze manier draagt big data bij aan het voorkomen van verdere ontbossing van waardevolle bossen.
De inzet van big data binnen de HCS Approach toont aan hoe digitale innovaties een belangrijke bijdrage kunnen leveren aan milieubescherming en duurzame bedrijfsvoering. Door middel van samenwerking en transparante datatoepassingen kunnen bedrijven en NGO’s samen een belangrijke stap zetten richting een meer verantwoorde omgang met natuurlijke hulpbronnen.
Link naar de bron: